你正在查看的文档所针对的是 Kubernetes 版本: v1.27
Kubernetes v1.27 版本的文档已不再维护。你现在看到的版本来自于一份静态的快照。如需查阅最新文档,请点击 最新版本。
Airflow 在 Kubernetes 中的使用(第一部分):一种不同的操作器
作者: Daniel Imberman (Bloomberg LP)
介绍
作为 Bloomberg 持续致力于开发 Kubernetes 生态系统的一部分, 我们很高兴能够宣布 Kubernetes Airflow Operator 的发布; Apache Airflow的一种机制,一种流行的工作流程编排框架, 使用 Kubernetes API 可以在本机启动任意的 Kubernetes Pod。
什么是 Airflow?
Apache Airflow 是“配置即代码”的 DevOps 理念的一种实现。 Airflow 允许用户使用简单的 Python 对象 DAG(有向无环图)启动多步骤流水线。 你可以在易于阅读的 UI 中定义依赖关系,以编程方式构建复杂的工作流,并监视调度的作业。
为什么在 Kubernetes 上使用 Airflow?
自成立以来,Airflow 的最大优势在于其灵活性。 Airflow 提供广泛的服务集成,包括Spark和HBase,以及各种云提供商的服务。 Airflow 还通过其插件框架提供轻松的可扩展性。 但是,该项目的一个限制是 Airflow 用户仅限于执行时 Airflow 站点上存在的框架和客户端。 单个组织可以拥有各种 Airflow 工作流程,范围从数据科学流到应用程序部署。 用例中的这种差异会在依赖关系管理中产生问题,因为两个团队可能会在其工作流程使用截然不同的库。
为了解决这个问题,我们使 Kubernetes 允许用户启动任意 Kubernetes Pod 和配置。 Airflow 用户现在可以在其运行时环境,资源和机密上拥有全部权限,基本上将 Airflow 转变为“你想要的任何工作”工作流程协调器。
Kubernetes Operator
在进一步讨论之前,我们应该澄清 Airflow 中的 Operator 是一个任务定义。 当用户创建 DAG 时,他们将使用像 “SparkSubmitOperator” 或 “PythonOperator” 这样的 Operator 分别提交/监视 Spark 作业或 Python 函数。 Airflow 附带了 Apache Spark,BigQuery,Hive 和 EMR 等框架的内置运算符。 它还提供了一个插件入口点,允许DevOps工程师开发自己的连接器。
Airflow 用户一直在寻找更易于管理部署和 ETL 流的方法。 在增加监控的同时,任何解耦流程的机会都可以减少未来的停机等问题。 以下是 Airflow Kubernetes Operator 提供的好处:
- 提高部署灵活性: Airflow 的插件 API一直为希望在其 DAG 中测试新功能的工程师提供了重要的福利。 不利的一面是,每当开发人员想要创建一个新的 Operator 时,他们就必须开发一个全新的插件。 现在,任何可以在 Docker 容器中运行的任务都可以通过完全相同的运算符访问,而无需维护额外的 Airflow 代码。
- 配置和依赖的灵活性:
对于在静态 Airflow 工作程序中运行的 Operator,依赖关系管理可能变得非常困难。 如果开发人员想要运行一个需要 SciPy 的任务和另一个需要 NumPy 的任务, 开发人员必须维护所有 Airflow 节点中的依赖关系或将任务卸载到其他计算机(如果外部计算机以未跟踪的方式更改,则可能导致错误)。 自定义 Docker 镜像允许用户确保任务环境,配置和依赖关系完全是幂等的。
- 使用kubernetes Secret以增加安全性: 处理敏感数据是任何开发工程师的核心职责。Airflow 用户总有机会在严格条款的基础上隔离任何API密钥,数据库密码和登录凭据。 使用 Kubernetes 运算符,用户可以利用 Kubernetes Vault 技术存储所有敏感数据。 这意味着 Airflow 工作人员将永远无法访问此信息,并且可以容易地请求仅使用他们需要的密码信息构建 Pod。
架构
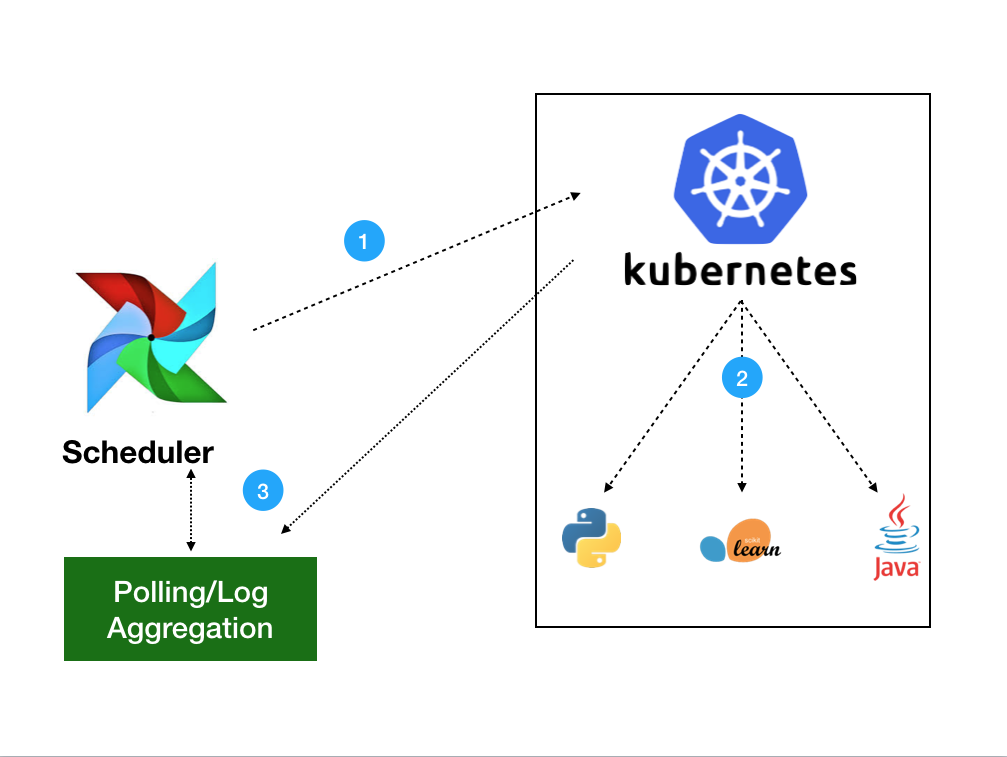
Kubernetes Operator 使用 Kubernetes Python客户端生成由 APIServer 处理的请求(1)。 然后,Kubernetes将使用你定义的需求启动你的 Pod(2)。 镜像文件中将加载环境变量,Secret 和依赖项,执行单个命令。 一旦启动作业,Operator 只需要监视跟踪日志的状况(3)。 用户可以选择将日志本地收集到调度程序或当前位于其 Kubernetes 集群中的任何分布式日志记录服务。
使用 Kubernetes Operator
一个基本的例子
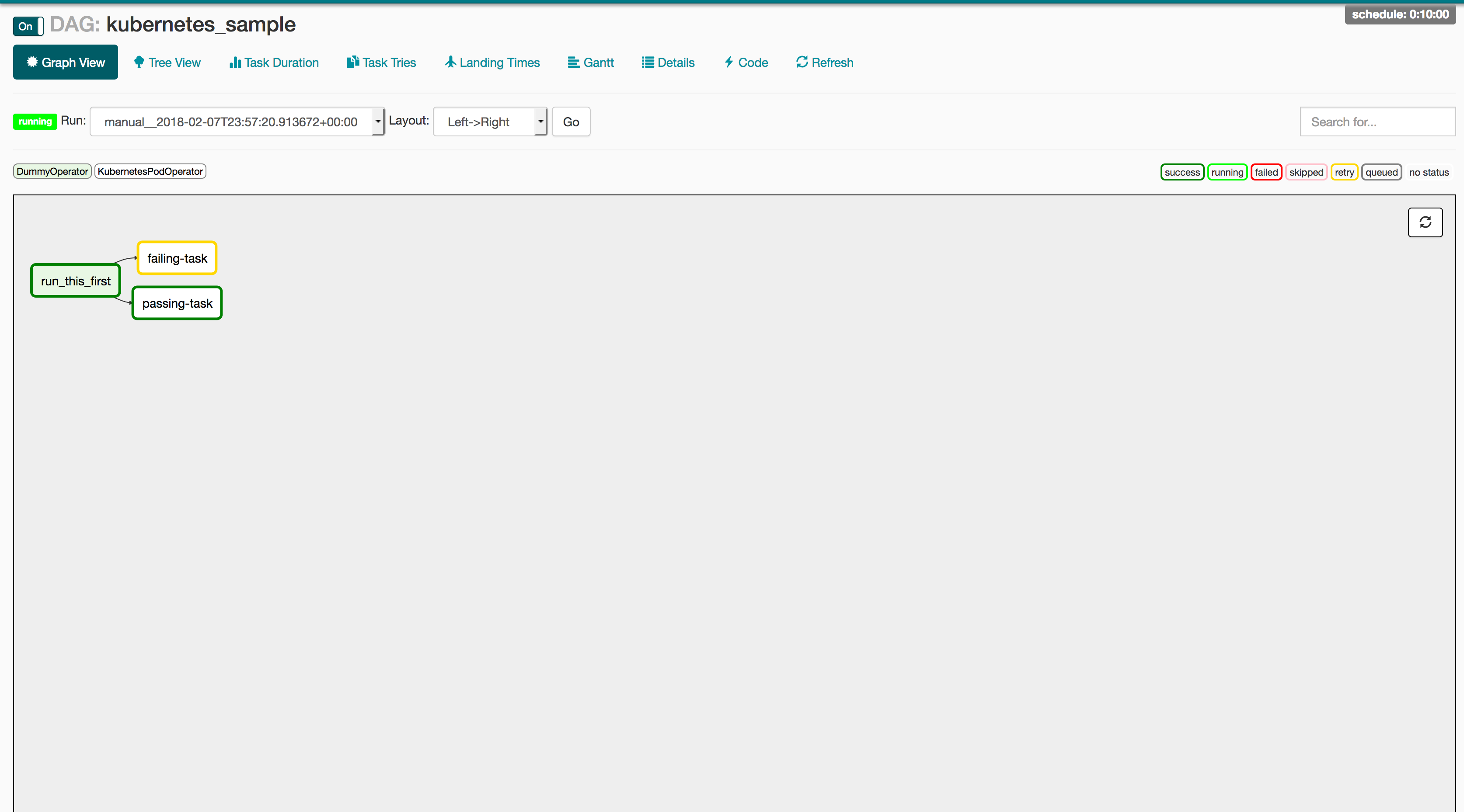
以下 DAG 可能是我们可以编写的最简单的示例,以显示 Kubernetes Operator 的工作原理。 这个 DAG 在 Kubernetes 上创建了两个 Pod:一个带有 Python 的 Linux 发行版和一个没有它的基本 Ubuntu 发行版。 Python Pod 将正确运行 Python 请求,而没有 Python 的那个将向用户报告失败。 如果 Operator 正常工作,则应该完成 “passing-task” Pod,而“ falling-task” Pod 则向 Airflow 网络服务器返回失败。
from airflow import DAG
from datetime import datetime, timedelta
from airflow.contrib.operators.kubernetes_pod_operator import KubernetesPodOperator
from airflow.operators.dummy_operator import DummyOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime.utcnow(),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
dag = DAG(
'kubernetes_sample', default_args=default_args, schedule_interval=timedelta(minutes=10))
start = DummyOperator(task_id='run_this_first', dag=dag)
passing = KubernetesPodOperator(namespace='default',
image="Python:3.6",
cmds=["Python","-c"],
arguments=["print('hello world')"],
labels={"foo": "bar"},
name="passing-test",
task_id="passing-task",
get_logs=True,
dag=dag
)
failing = KubernetesPodOperator(namespace='default',
image="ubuntu:1604",
cmds=["Python","-c"],
arguments=["print('hello world')"],
labels={"foo": "bar"},
name="fail",
task_id="failing-task",
get_logs=True,
dag=dag
)
passing.set_upstream(start)
failing.set_upstream(start)
但这与我的工作流程有什么关系?
虽然这个例子只使用基本映像,但 Docker 的神奇之处在于,这个相同的 DAG 可以用于你想要的任何图像/命令配对。 以下是推荐的 CI/CD 管道,用于在 Airflow DAG 上运行生产就绪代码。
1:github 中的 PR
使用Travis或Jenkins运行单元和集成测试,请你的朋友PR你的代码,并合并到主分支以触发自动CI构建。
2:CI/CD 构建 Jenkins - > Docker 镜像
在 Jenkins 构建中生成 Docker 镜像和更新版本。
3:Airflow 启动任务
最后,更新你的 DAG 以反映新版本,你应该准备好了!
production_task = KubernetesPodOperator(namespace='default',
# image="my-production-job:release-1.0.1", <-- old release
image="my-production-job:release-1.0.2",
cmds=["Python","-c"],
arguments=["print('hello world')"],
name="fail",
task_id="failing-task",
get_logs=True,
dag=dag
)
启动测试部署
由于 Kubernetes Operator 尚未发布,我们尚未发布官方 helm 图表或 Operator(但两者目前都在进行中)。 但是,我们在下面列出了基本部署的说明,并且正在积极寻找测试人员来尝试这一新功能。 要试用此系统,请按以下步骤操作:
步骤1:将 kubeconfig 设置为指向 kubernetes 集群
步骤2:克隆 Airflow 仓库:
运行 git clone https://github.com/apache/incubator-airflow.git 来克隆官方 Airflow 仓库。
步骤3:运行
为了运行这个基本 Deployment,我们正在选择我们目前用于 Kubernetes Executor 的集成测试脚本(将在本系列的下一篇文章中对此进行解释)。 要启动此部署,请运行以下三个命令:
sed -ie "s/KubernetesExecutor/LocalExecutor/g" scripts/ci/kubernetes/kube/configmaps.yaml
./scripts/ci/kubernetes/Docker/build.sh
./scripts/ci/kubernetes/kube/deploy.sh
在我们继续之前,让我们讨论这些命令正在做什么:
sed -ie "s/KubernetesExecutor/LocalExecutor/g" scripts/ci/kubernetes/kube/configmaps.yaml
Kubernetes Executor 是另一种 Airflow 功能,允许动态分配任务已解决幂等 Pod 的问题。 我们将其切换到 LocalExecutor 的原因只是一次引入一个功能。 如果你想尝试 Kubernetes Executor,欢迎你跳过此步骤,但我们将在以后的文章中详细介绍。
./scripts/ci/kubernetes/Docker/build.sh
此脚本将对Airflow主分支代码进行打包,以根据Airflow的发行文件构建Docker容器
./scripts/ci/kubernetes/kube/deploy.sh
最后,我们在你的集群上创建完整的Airflow部署。这包括 Airflow 配置,postgres 后端,web 服务器和调度程序以及之间的所有必要服务。 需要注意的一点是,提供的角色绑定是集群管理员,因此如果你没有该集群的权限级别,可以在 scripts/ci/kubernetes/kube/airflow.yaml 中进行修改。
步骤4:登录你的网络服务器
现在你的 Airflow 实例正在运行,让我们来看看 UI! 用户界面位于 Airflow Pod的 8080 端口,因此只需运行即可:
WEB=$(kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}' | grep "airflow" | head -1)
kubectl port-forward $WEB 8080:8080
现在,Airflow UI 将存在于 http://localhost:8080上。
要登录,只需输入airflow/airflow,你就可以完全访问 Airflow Web UI。
步骤5:上传测试文档
要修改/添加自己的 DAG,可以使用 kubectl cp 将本地文件上传到 Airflow 调度程序的 DAG 文件夹中。
然后,Airflow 将读取新的 DAG 并自动将其上传到其系统。以下命令将任何本地文件上载到正确的目录中:
kubectl cp <local file> <namespace>/<pod>:/root/airflow/dags -c scheduler
步骤6:使用它!
那么我什么时候可以使用它?
虽然此功能仍处于早期阶段,但我们希望在未来几个月内发布该功能以进行广泛发布。
参与其中
此功能只是将 Apache Airflow 集成到 Kubernetes 中的多项主要工作的开始。 Kubernetes Operator 已合并到 Airflow 的 1.10 发布分支(实验模式中的执行模块), 以及完整的 k8s 本地调度程序称为 Kubernetes Executor(即将发布文章)。 这些功能仍处于早期采用者/贡献者可能对这些功能的未来产生巨大影响的阶段。
对于有兴趣加入这些工作的人,我建议按照以下步骤:
- 加入 airflow-dev 邮件列表 dev@airflow.apache.org。
- 在 Apache Airflow JIRA中提出问题
- 周三上午 10点 太平洋标准时间加入我们的 SIG-BigData 会议。
- 在 kubernetes.slack.com 上的 #sig-big-data 找到我们。
特别感谢 Apache Airflow 和 Kubernetes 社区,特别是 Grant Nicholas,Ben Goldberg,Anirudh Ramanathan,Fokko Dreisprong 和 Bolke de Bruin, 感谢你对这些功能的巨大帮助以及我们未来的努力。