You are viewing documentation for Kubernetes version: v1.27
Kubernetes v1.27 documentation is no longer actively maintained. The version you are currently viewing is a static snapshot. For up-to-date information, see the latest version.
KubeDirector: The easy way to run complex stateful applications on Kubernetes
Author: Thomas Phelan (BlueData)
KubeDirector is an open source project designed to make it easy to run complex stateful scale-out application clusters on Kubernetes. KubeDirector is built using the custom resource definition (CRD) framework and leverages the native Kubernetes API extensions and design philosophy. This enables transparent integration with Kubernetes user/resource management as well as existing clients and tools.
We recently introduced the KubeDirector project, as part of a broader open source Kubernetes initiative we call BlueK8s. I’m happy to announce that the pre-alpha code for KubeDirector is now available. And in this blog post, I’ll show how it works.
KubeDirector provides the following capabilities:
- The ability to run non-cloud native stateful applications on Kubernetes without modifying the code. In other words, it’s not necessary to decompose these existing applications to fit a microservices design pattern.
- Native support for preserving application-specific configuration and state.
- An application-agnostic deployment pattern, minimizing the time to onboard new stateful applications to Kubernetes.
KubeDirector enables data scientists familiar with data-intensive distributed applications such as Hadoop, Spark, Cassandra, TensorFlow, Caffe2, etc. to run these applications on Kubernetes -- with a minimal learning curve and no need to write GO code. The applications controlled by KubeDirector are defined by some basic metadata and an associated package of configuration artifacts. The application metadata is referred to as a KubeDirectorApp resource.
To understand the components of KubeDirector, clone the repository on GitHub using a command similar to:
git clone http://<userid>@github.com/bluek8s/kubedirector.
The KubeDirectorApp definition for the Spark 2.2.1 application is located
in the file kubedirector/deploy/example_catalog/cr-app-spark221e2.json.
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{
"apiVersion": "kubedirector.bluedata.io/v1alpha1",
"kind": "KubeDirectorApp",
"metadata": {
"name" : "spark221e2"
},
"spec" : {
"systemctlMounts": true,
"config": {
"node_services": [
{
"service_ids": [
"ssh",
"spark",
"spark_master",
"spark_worker"
],
…
The configuration of an application cluster is referred to as a KubeDirectorCluster resource. The
KubeDirectorCluster definition for a sample Spark 2.2.1 cluster is located in the file
kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml.
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1"
kind: "KubeDirectorCluster"
metadata:
name: "spark221e2"
spec:
app: spark221e2
roles:
- name: controller
replicas: 1
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: worker
replicas: 2
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: jupyter
…
Running Spark on Kubernetes with KubeDirector
With KubeDirector, it’s easy to run Spark clusters on Kubernetes.
First, verify that Kubernetes (version 1.9 or later) is running, using the command kubectl version
~> kubectl version
Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Deploy the KubeDirector service and the example KubeDirectorApp resource definitions with the commands:
cd kubedirector
make deploy
These will start the KubeDirector pod:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
List the installed KubeDirector applications with kubectl get KubeDirectorApp
~> kubectl get KubeDirectorApp
NAME AGE
cassandra311 30m
spark211up 30m
spark221e2 30m
Now you can launch a Spark 2.2.1 cluster using the example KubeDirectorCluster file and the
kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml command.
Verify that the Spark cluster has been started:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-djdwl 1/1 Running 0 19m
spark221e2-controller-zbg4d-0 1/1 Running 0 23m
spark221e2-jupyter-2km7q-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-1 1/1 Running 0 23m
The running services now include the Spark services:
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
Pointing the browser at port 31533 connects to the Spark Master UI:
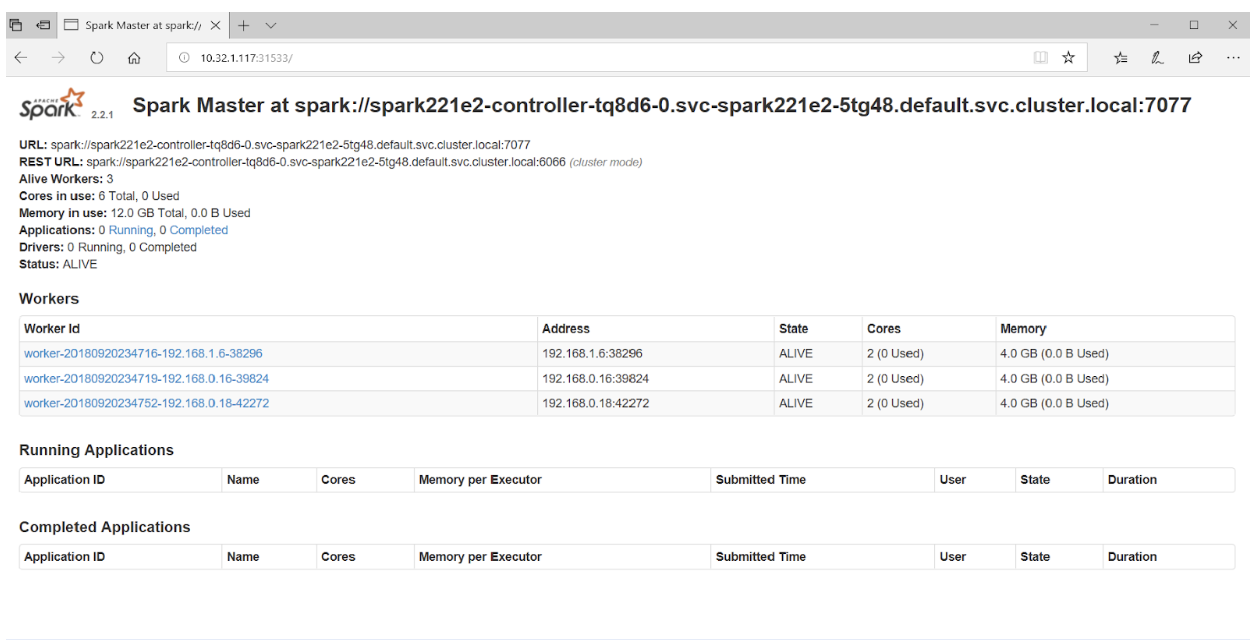
That’s all there is to it! In fact, in the example above we also deployed a Jupyter notebook along with the Spark cluster.
To start another application (e.g. Cassandra), just specify another KubeDirectorApp file:
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
See the running Cassandra cluster:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
cassandra311-seed-v24r6-0 1/1 Running 0 1m
cassandra311-seed-v24r6-1 1/1 Running 0 1m
cassandra311-worker-rqrhl-0 1/1 Running 0 1m
cassandra311-worker-rqrhl-1 1/1 Running 0 1m
kubedirector-58cf59869-djdwl 1/1 Running 0 1d
spark221e2-controller-tq8d6-0 1/1 Running 0 22m
spark221e2-jupyter-6989v-0 1/1 Running 0 22m
spark221e2-worker-d9892-0 1/1 Running 0 22m
spark221e2-worker-d9892-1 1/1 Running 0 22m
Now you have a Spark cluster (with a Jupyter notebook) and a Cassandra cluster running on Kubernetes.
Use kubectl get service to see the set of services.
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m
svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m
svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m
svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m
svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
Get Involved
KubeDirector is a fully open source, Apache v2 licensed, project – the first of multiple open source projects within a broader initiative we call BlueK8s. The pre-alpha code for KubeDirector has just been released and we would love for you to join the growing community of developers, contributors, and adopters. Follow @BlueK8s on Twitter and get involved through these channels:
- KubeDirector chat room on Slack
- KubeDirector GitHub repo