You are viewing documentation for Kubernetes version: v1.27
Kubernetes v1.27 documentation is no longer actively maintained. The version you are currently viewing is a static snapshot. For up-to-date information, see the latest version.
Gardener Project Update
Authors: Rafael Franzke (SAP), Vasu Chandrasekhara (SAP)
Last year, we introduced Gardener in the Kubernetes Community Meeting and in a post on the Kubernetes Blog. At SAP, we have been running Gardener for more than two years, and are successfully managing thousands of conformant clusters in various versions on all major hyperscalers as well as in numerous infrastructures and private clouds that typically join an enterprise via acquisitions.
We are often asked why a handful of dynamically scalable clusters would not suffice. We also started our journey into Kubernetes with a similar mindset. But we realized that applying the architecture and principles of Kubernetes to productive scenarios, our internal and external customers very quickly required the rational separation of concerns and ownership, which in most circumstances led to the use of multiple clusters. Therefore, a scalable and managed Kubernetes as a service solution is often also the basis for adoption. Particularly, when a larger organization runs multiple products on different providers and in different regions, the number of clusters will quickly rise to the hundreds or even thousands.
Today, we want to give an update on what we have implemented in the past year regarding extensibility and customizability, and what we plan to work on for our next milestone.
Short Recap: What Is Gardener?
Gardener's main principle is to leverage Kubernetes primitives for all of its
operations, commonly described as inception or kubeception. The feedback from
the community was that initially our architecture
diagram looks
"overwhelming", but after some little digging into the material, everything we
do is the "Kubernetes way". One can re-use all learnings with respect to APIs,
control loops, etc.
The essential idea is that so-called seed clusters are used to host the
control planes of end-user clusters (botanically named shoots).
Gardener provides vanilla Kubernetes clusters as a service independent of the
underlying infrastructure provider in a homogenous way, utilizing the upstream
provided k8s.gcr.io/* images as open distribution (update: k8s.gcr.io has been deprecated in favor of registry.k8s.io). The project is built
entirely on top of Kubernetes extension concepts, and as such adds a custom API
server, a controller-manager, and a scheduler to create and manage the lifecycle
of Kubernetes clusters. It extends the Kubernetes API with custom resources,
most prominently the Gardener cluster specification (Shoot resource), that can
be used to "order" a Kubernetes cluster in a declarative way (for day-1, but
also reconcile all management activities for day-2).
By leveraging Kubernetes as base infrastructure, we were able to devise a combined Horizontal and Vertical Pod Autoscaler (HVPA) that, when configured with custom heuristics, scales all control plane components up/down or out/in automatically. This enables a fast scale-out, even beyond the capacity of typically some fixed number of master nodes. This architectural feature is one of the main differences compared to many other Kubernetes cluster provisioning tools. But in our production, Gardener does not only effectively reduce the total costs of ownership by bin-packing control planes. It also simplifies implementation of "day-2 operations" (like cluster updates or robustness qualities). Again, essentially by relying on all the mature Kubernetes features and capabilities.
The newly introduced extension concepts for Gardener now enable providers to only maintain their specific extension without the necessity to develop inside the core source tree.
Extensibility
As result of its growth over the past years, the Kubernetes code base contained a numerous amount of provider-specific code that is now being externalized from its core source tree. The same has happened with Project Gardener: over time, lots of specifics for cloud providers, operating systems, network plugins, etc. have been accumulated. Generally, this leads to a significant increase of efforts when it comes to maintainability, testability, or to new releases. Our community member Packet contributed Gardener support for their infrastructure in-tree, and suffered from the mentioned downsides.
Consequently, similar to how the Kubernetes community decided to move their cloud-controller-managers out-of-tree, or volumes plugins to CSI, etc., the Gardener community proposed and implemented likewise extension concepts. The Gardener core source-tree is now devoid of any provider specifics, allowing vendors to solely focus on their infrastructure specifics, and enabling core contributors becoming more agile again.
Typically, setting up a cluster requires a flow of interdependent steps, beginning with the generation of certificates and preparation of the infrastructure, continuing with the provisioning of the control plane and the worker nodes, and ending with the deployment of system components. We would like to emphasize here that all these steps are necessary (cf. Kubernetes the Hard Way) and all Kubernetes cluster creation tools implement the same steps (automated to some degree) in one way or another.
The general idea of Gardener's extensibility concept was to make this flow more generic and to carve out custom resources for each step which can serve as ideal extension points.
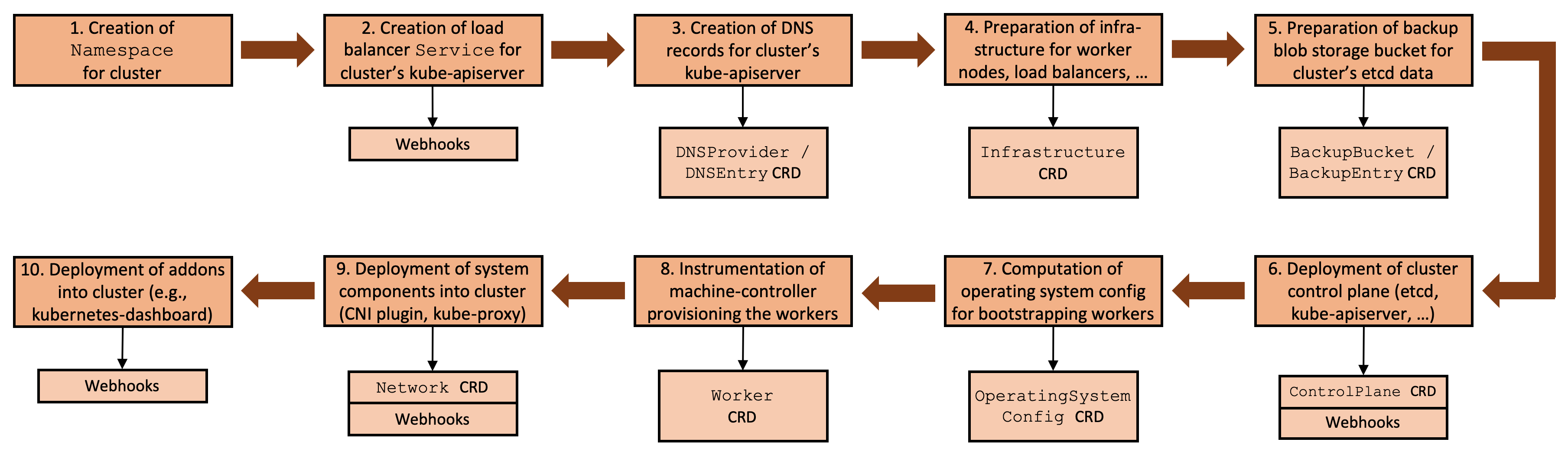
Figure 1 Cluster reconciliation flow with extension points.
With Gardener's flow framework we implicitly have a reproducible state machine for all infrastructures and all possible states of a cluster.
The Gardener extensibility approach defines custom resources that serve as ideal extension points for the following categories:
- DNS providers (e.g., Route53, CloudDNS, ...),
- Blob storage providers (e.g., S3, GCS, ABS,...),
- Infrastructure providers (e.g., AWS, GCP, Azure, ...),
- Operating systems (e.g., CoreOS Container Linux, Ubuntu, FlatCar Linux, ...),
- Network plugins (e.g., Calico, Flannel, Cilium, ...),
- Non-essential extensions (e.g., Let's Encrypt certificate service).
Extension Points
Besides leveraging custom resource definitions, we also effectively use mutating
/ validating webhooks in the seed clusters. Extension controllers themselves run
in these clusters and react on CRDs and workload resources (like Deployment,
StatefulSet, etc.) they are responsible for. Similar to the Cluster
API's approach, these CRDs may also contain
provider specific information.
The steps 2. - 10. [cf. Figure 1] involve infrastructure specific meta data
referring to infrastructure specific implementations, e.g. for DNS records there
might be aws-route53, google-clouddns, or for isolated networks even
openstack-designate, and many more. We are going to examine the steps 4 and 6
in the next paragraphs as examples for the general concepts (based on the
implementation for AWS). If you're interested you can read up the fully
documented API contract in our extensibility
documents.
Example: Infrastructure CRD
Kubernetes clusters on AWS require a certain infrastructure preparation before
they can be used. This includes, for example, the creation of a VPC, subnets,
etc. The purpose of the Infrastructure CRD is to trigger this preparation:
apiVersion: extensions.gardener.cloud/v1alpha1
kind: Infrastructure
metadata:
name: infrastructure
namespace: shoot--foobar--aws
spec:
type: aws
region: eu-west-1
secretRef:
name: cloudprovider
namespace: shoot--foobar—aws
sshPublicKey: c3NoLXJzYSBBQUFBQ...
providerConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vpc:
cidr: 10.250.0.0/16
zones:
- name: eu-west-1a
internal: 10.250.112.0/22
public: 10.250.96.0/22
workers: 10.250.0.0/19
Based on the Shoot resource, Gardener creates this Infrastructure resource
as part of its reconciliation flow. The AWS-specific providerConfig is part of
the end-user's configuration in the Shoot resource and not evaluated by
Gardener but just passed to the extension controller in the seed cluster.
In its current implementation, the AWS extension creates a new VPC and three
subnets in the eu-west-1a zones. Also, it creates a NAT and an internet
gateway, elastic IPs, routing tables, security groups, IAM roles, instances
profiles, and an EC2 key pair.
After it has completed its tasks it will report the status and some provider-specific output:
apiVersion: extensions.gardener.cloud/v1alpha1
kind: Infrastructure
metadata:
name: infrastructure
namespace: shoot--foobar--aws
spec: ...
status:
lastOperation:
type: Reconcile
state: Succeeded
providerStatus:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureStatus
ec2:
keyName: shoot--foobar--aws-ssh-publickey
iam:
instanceProfiles:
- name: shoot--foobar--aws-nodes
purpose: nodes
roles:
- arn: "arn:aws:iam::<accountID>:role/shoot..."
purpose: nodes
vpc:
id: vpc-0815
securityGroups:
- id: sg-0246
purpose: nodes
subnets:
- id: subnet-1234
purpose: nodes
zone: eu-west-1b
- id: subnet-5678
purpose: public
zone: eu-west-1b
The information inside the providerStatus can be used in subsequent steps,
e.g. to configure the cloud-controller-manager or to instrument the
machine-controller-manager.
Example: Deployment of the Cluster Control Plane
One of the major features of Gardener is the homogeneity of the clusters it
manages across different infrastructures. Consequently, it is still in charge of
deploying the provider-independent control plane components into the seed
cluster (like etcd, kube-apiserver). The deployment of provider-specific control
plane components like cloud-controller-manager or CSI controllers is triggered
by a dedicated ControlPlane CRD. In this paragraph, however, we want to focus
on the customization of the standard components.
Let's focus on both the kube-apiserver and the kube-controller-manager
Deployments. Our AWS extension for Gardener is not yet using CSI but relying
on the in-tree EBS volume plugin. Hence, it needs to enable the
PersistentVolumeLabel admission plugin and to provide the cloud provider
config to the kube-apiserver. Similarly, the kube-controller-manager will be
instructed to use its in-tree volume plugin.
The kube-apiserver Deployment incorporates the kube-apiserver container and
is deployed by Gardener like this:
containers:
- command:
- /hyperkube
- apiserver
- --enable-admission-plugins=Priority,...,NamespaceLifecycle
- --allow-privileged=true
- --anonymous-auth=false
...
Using a MutatingWebhookConfiguration the AWS extension injects the mentioned
flags and modifies the spec as follows:
containers:
- command:
- /hyperkube
- apiserver
- --enable-admission-plugins=Priority,...,NamespaceLifecycle,PersistentVolumeLabel
- --allow-privileged=true
- --anonymous-auth=false
...
- --cloud-provider=aws
- --cloud-config=/etc/kubernetes/cloudprovider/cloudprovider.conf
- --endpoint-reconciler-type=none
...
volumeMounts:
- mountPath: /etc/kubernetes/cloudprovider
name: cloud-provider-config
volumes:
- configMap:
defaultMode: 420
name: cloud-provider-config
name: cloud-provider-config
The kube-controller-manager Deployment is handled in a similar way.
Webhooks in the seed cluster can be used to mutate anything related to the shoot cluster control plane deployed by Gardener or any other extension. There is a similar webhook concept for resources in shoot clusters in case extension controllers need to customize system components deployed by Gardener.
Registration of Extension Controllers
The Gardener API uses two special resources to register and install extensions.
The registration itself is declared via the ControllerRegistration resource.
The easiest option is to define the Helm chart as well as some values to render
the chart, however, any other deployment mechanism is supported via custom code
as well.
Gardener determines whether an extension controller is required in a specific
seed cluster, and creates a ControllerInstallation that is used to trigger the
deployment.
To date, every registered extension controller is deployed to every seed cluster which is not necessary in general. In the future, Gardener will become more selective to only deploy those extensions required on the specific seed clusters.
Our dynamic registration approach allows to add or remove extensions in the running system - without the necessity to rebuild or restart any component.
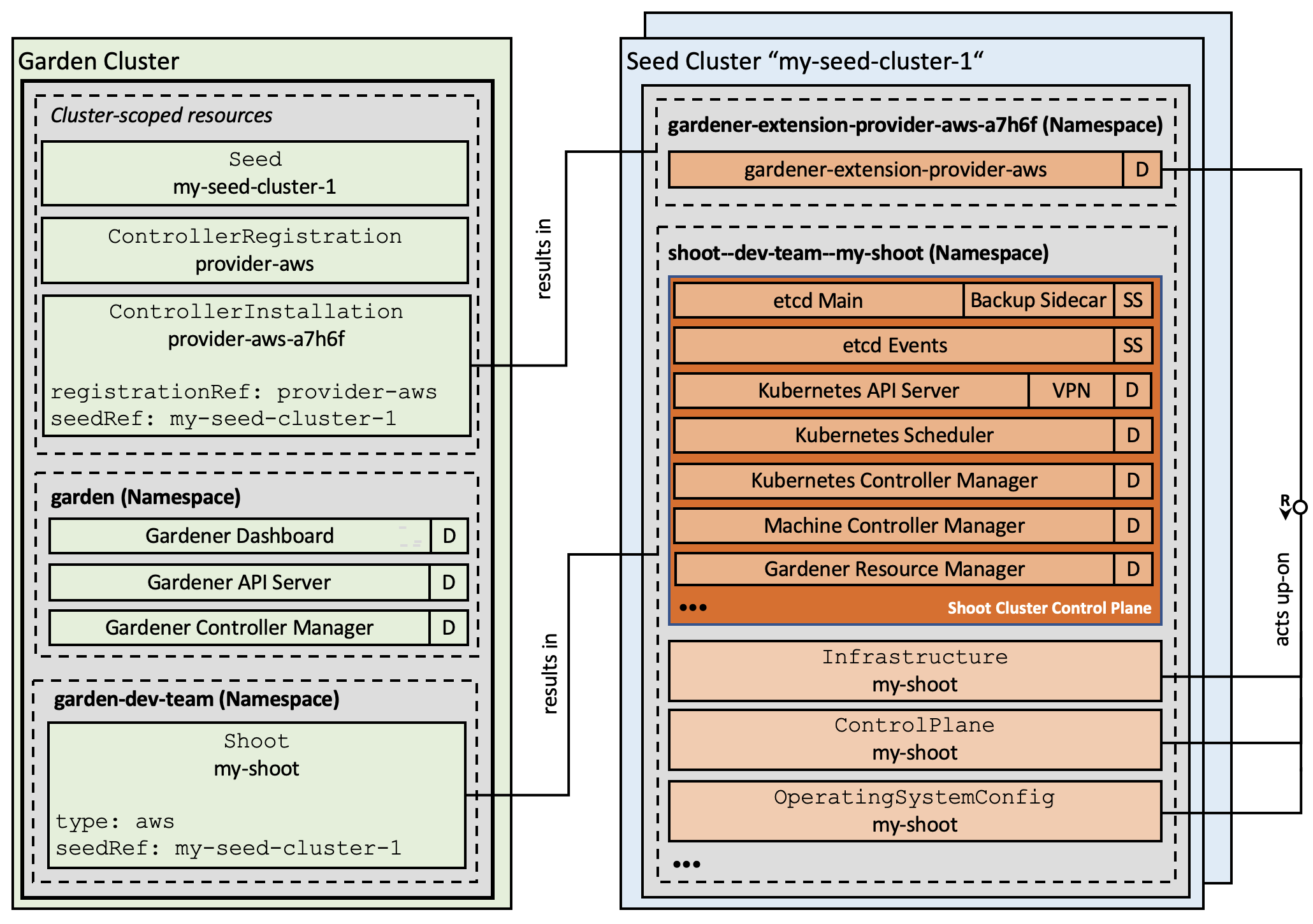
Figure 2 Gardener architecture with extension controllers.
Status Quo
We have recently introduced the new core.gardener.cloud API group that
incorporates fully forwards and backwards compatible Shoot resources, and that
allows providers to use Gardener without modifying anything in its core source
tree.
We have already adapted all controllers to use this new API group and have deprecated the old API. Eventually, after a few months we will remove it, so end-users are advised to start migrating to the new API soon.
Apart from that, we have enabled all relevant extensions to contribute to the
shoot health status and implemented the respective contract. The basic idea is
that the CRDs may have .status.conditions that are picked up by Gardener and
merged with its standard health checks into the Shoot status field.
Also, we want to implement some easy-to-use library functions facilitating
defaulting and validation webhooks for the CRDs in order to validate the
providerConfig field controlled by end-users.
Finally, we will split the
gardener/gardener-extensions
repository into separate repositories and keep it only for the generic library
functions that can be used to write extension controllers.
Next Steps
Kubernetes has externalized many of the infrastructural management challenges. The inception design solves most of them by delegating lifecycle operations to a separate management plane (seed clusters). But what if the garden cluster or a seed cluster goes down? How do we scale beyond tens of thousands of managed clusters that need to be reconciled in parallel? We are further investing into hardening the Gardener scalability and disaster recovery features. Let's briefly highlight three of the features in more detail:
Gardenlet
Right from the beginning of the Gardener Project we started implementing the operator pattern: We have a custom controller-manager that acts on our own custom resources. Now, when you start thinking about the Gardener architecture, you will recognize some interesting similarity with respect to the Kubernetes architecture: Shoot clusters can be compared with pods, and seed clusters can be seen as worker nodes. Guided by this observation we introduced the gardener-scheduler. Its main task is to find an appropriate seed cluster to host the control-plane for newly ordered clusters, similar to how the kube-scheduler finds an appropriate node for newly created pods. By providing multiple seed clusters for a region (or provider) and distributing the workload, we reduce the blast-radius of potential hick-ups as well.
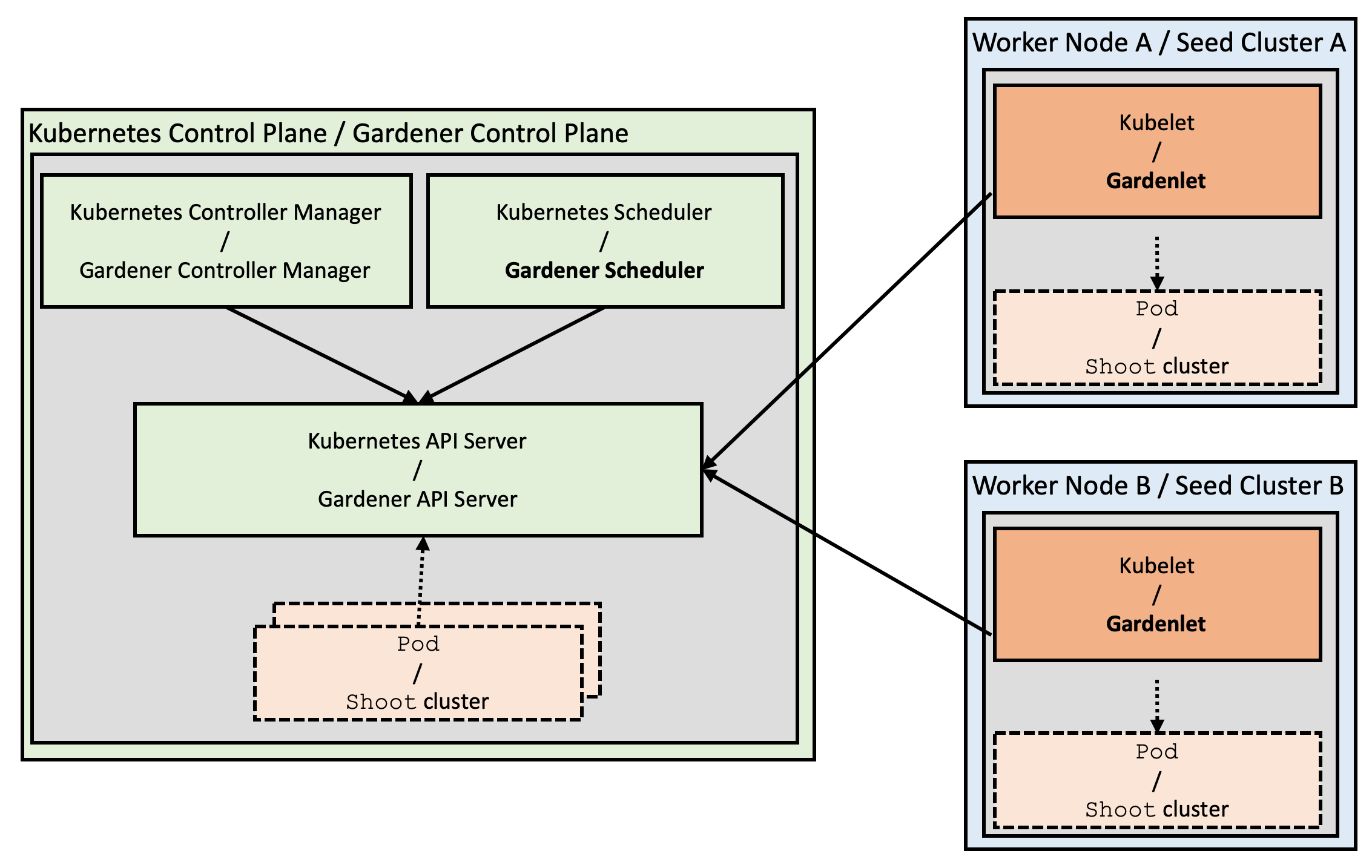
Figure 3 Similarities between Kubernetes and Gardener architecture.
Yet, there is still a significant difference between the Kubernetes and the Gardener architectures: Kubernetes runs a primary "agent" on every node, the kubelet, which is mainly responsible for managing pods and containers on its particular node. Gardener uses its controller-manager which is responsible for all shoot clusters on all seed clusters, and it is performing its reconciliation loops centrally from the garden cluster.
While this works well at scale for thousands of clusters today, our goal is to enable true scalability following the Kubernetes principles (beyond the capacity of a single controller-manager): We are now working on distributing the logic (or the Gardener operator) into the seed cluster and will introduce a corresponding component, adequately named the gardenlet. It will be Gardener's primary "agent" on every seed cluster and will be only responsible for shoot clusters located in its particular seed cluster.
The gardener-controller-manager will still keep its control loops for other resources of the Gardener API, however, it will no longer talk to seed/shoot clusters.
Reversing the control flow will even allow placing seed/shoot clusters behind firewalls without the necessity of direct accessibility (via VPN tunnels) anymore.
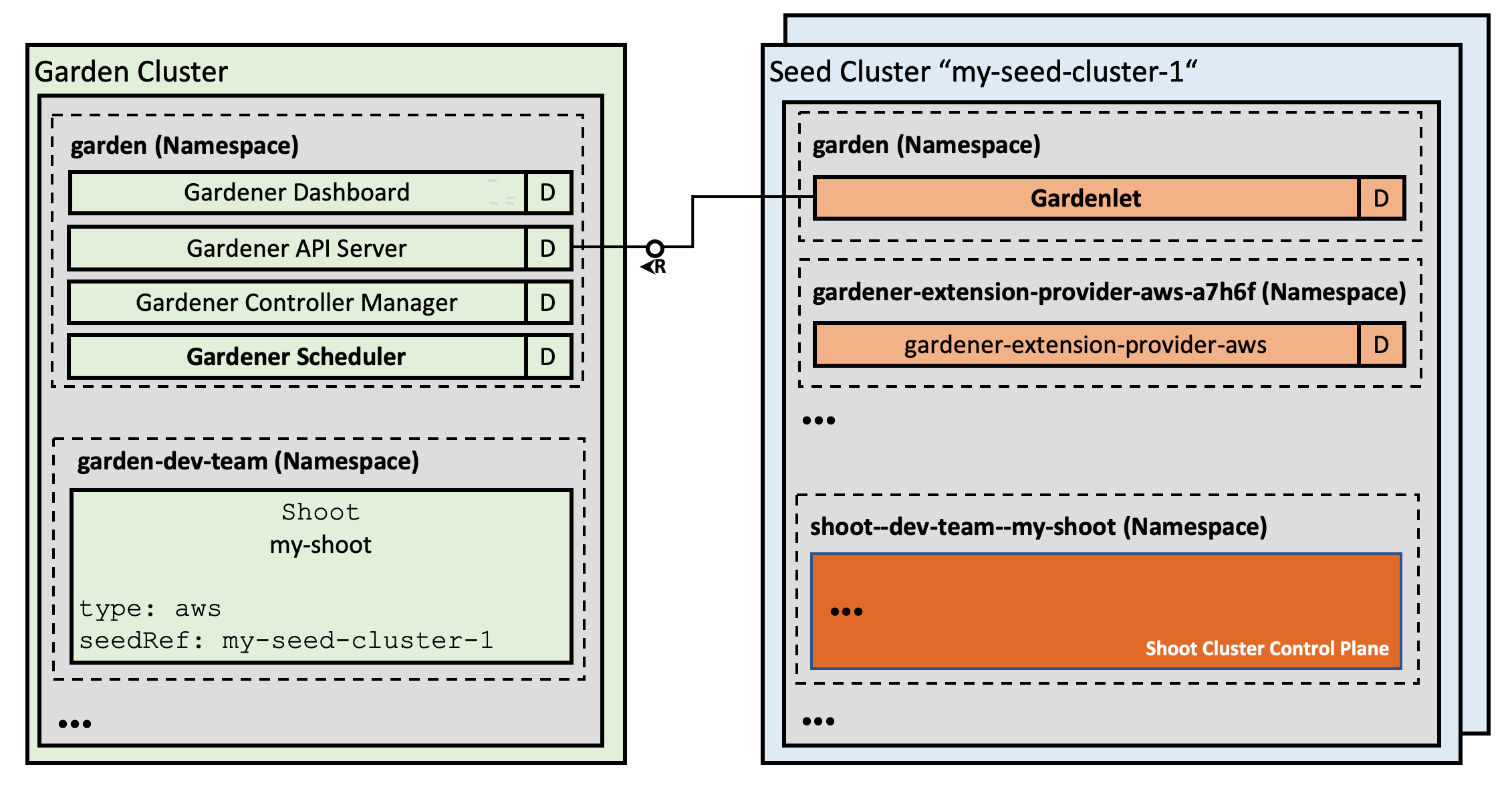
Figure 4 Detailed architecture with Gardenlet.
Control Plane Migration between Seed Clusters
When a seed cluster fails, the user's static workload will continue to operate. However, administrating the cluster won't be possible anymore because the shoot cluster's API server running in the failed seed is no longer reachable.
We have implemented the relocation of failed control planes hit by some seed disaster to another seed and are now working on fully automating this unique capability. In fact, this approach is not only feasible, we have performed the fail-over procedure multiple times in our production.
The automated failover capability will enable us to implement even more comprehensive disaster recovery and scalability qualities, e.g., the automated provisioning and re-balancing of seed clusters or automated migrations for all non-foreseeable cases. Again, think about the similarities with Kubernetes with respect to pod eviction and node drains.
Gardener Ring
The Gardener Ring is our novel approach for provisioning and managing Kubernetes clusters without relying on an external provision tool for the initial cluster. By using Kubernetes in a recursive manner, we can drastically reduce the management complexity by avoiding imperative tool sets, while creating new qualities with a self-stabilizing circular system.
The Ring approach is conceptually different from self-hosting and static pod based deployments. The idea is to create a ring of three (or more) shoot clusters that each host the control plane of its successor.
An outage of one cluster will not affect the stability and availability of the
Ring, and as the control plane is externalized the failed cluster can be
automatically recovered by Gardener's self-healing capabilities. As long as
there is a quorum of at least n/2+1 available clusters the Ring will always
stabilize itself. Running these clusters on different cloud providers (or at
least in different regions / data centers) reduces the potential for quorum
losses.
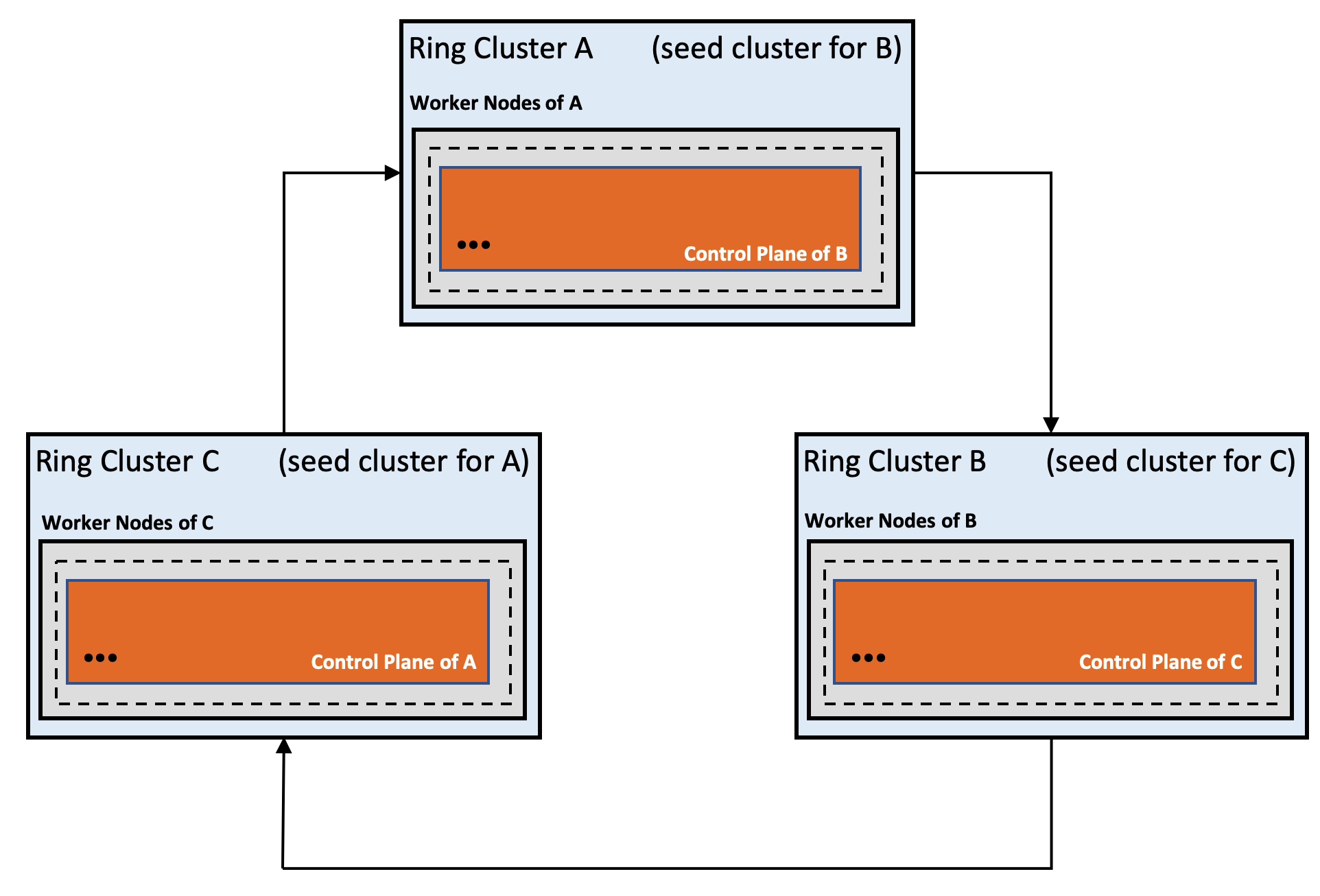
Figure 5 Self-stabilizing ring of Kubernetes clusters.
The way how the distributed instances of Gardener can share the same data is by deploying separate kube-apiserver instances talking to the same etcd cluster. These kube-apiservers are forming a node-less Kubernetes cluster that can be used as "data container" for Gardener and its associated applications.
We are running test landscapes internally protected by the ring and it has saved us from manual interventions. With the automated control plane migration in place we can easily bootstrap the Ring and will solve the "initial cluster problem" as well as improve the overall robustness.
Getting Started!
If you are interested in writing an extension, you might want to check out the following resources:
- GEP-1: Extensibility proposal document
- GEP-4: New
core.gardener.cloud/v1alpha1API - Example extension controller implementation for AWS
- Gardener Extensions Golang library
- Extension contract documentation
- Gardener API Reference
Of course, any other contribution to our project is very welcome as well! We are always looking for new community members.
If you want to try out Gardener, please check out our quick installation guide. This installer will setup a complete Gardener environment ready to be used for testing and evaluation within just a few minutes.
Contributions Welcome!
The Gardener project is developed as Open Source and hosted on GitHub: https://github.com/gardener
If you see the potential of the Gardener project, please join us via GitHub.
We are having a weekly public community meeting scheduled every Friday 10-11 a.m. CET, and a public #gardener Slack channel in the Kubernetes workspace. Also, we are planning a Gardener Hackathon in Q1 2020 and are looking forward meeting you there!